Introduction to Data Analysis Lesson 5 Data Analysis Process - Case Study 2: Cleaning Column Labels
Published
•1 min readCleaning Column Labels
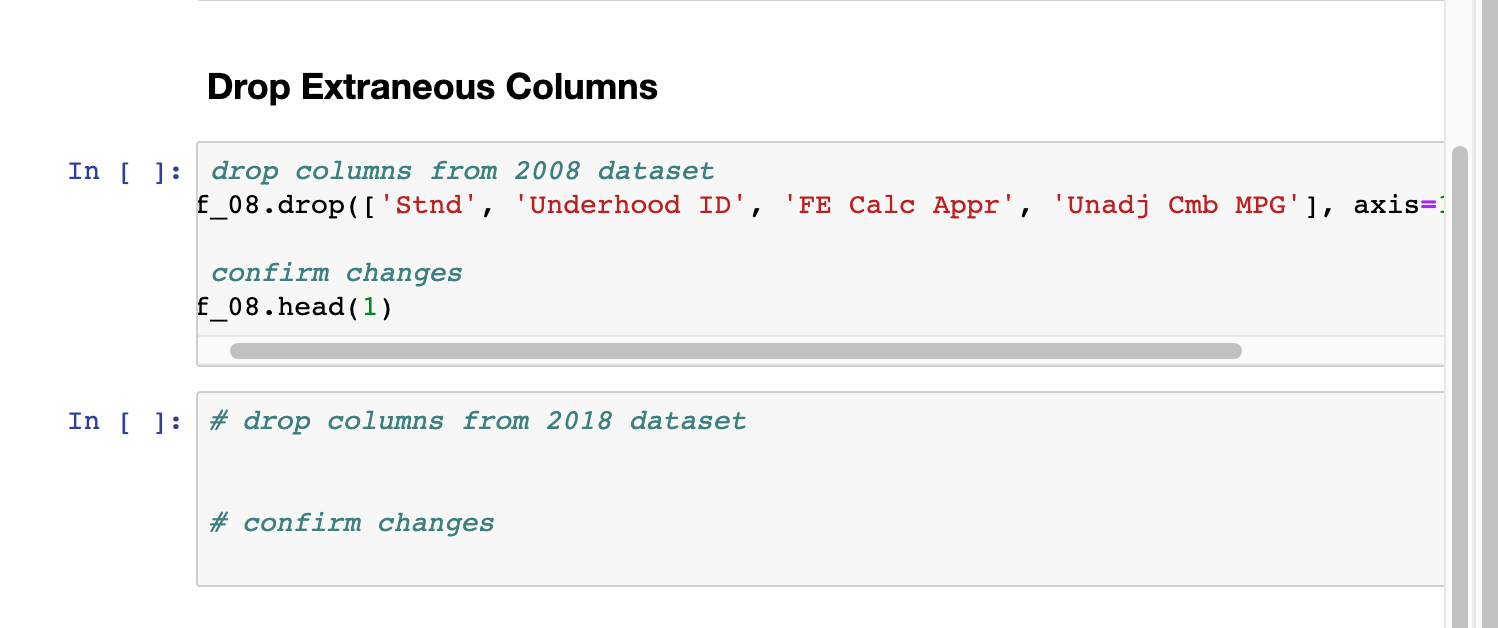
1. Drop extraneous columns
Drop features that aren't consistent (not present in both datasets) or aren't relevant to our questions. Use pandas' drop function.
Columns to Drop:
- From 2008 dataset:
'Stnd', 'Underhood ID', 'FE Calc Appr', 'Unadj Cmb MPG' - From 2018 dataset:
'Stnd', 'Stnd Description', 'Underhood ID', 'Comb CO2'
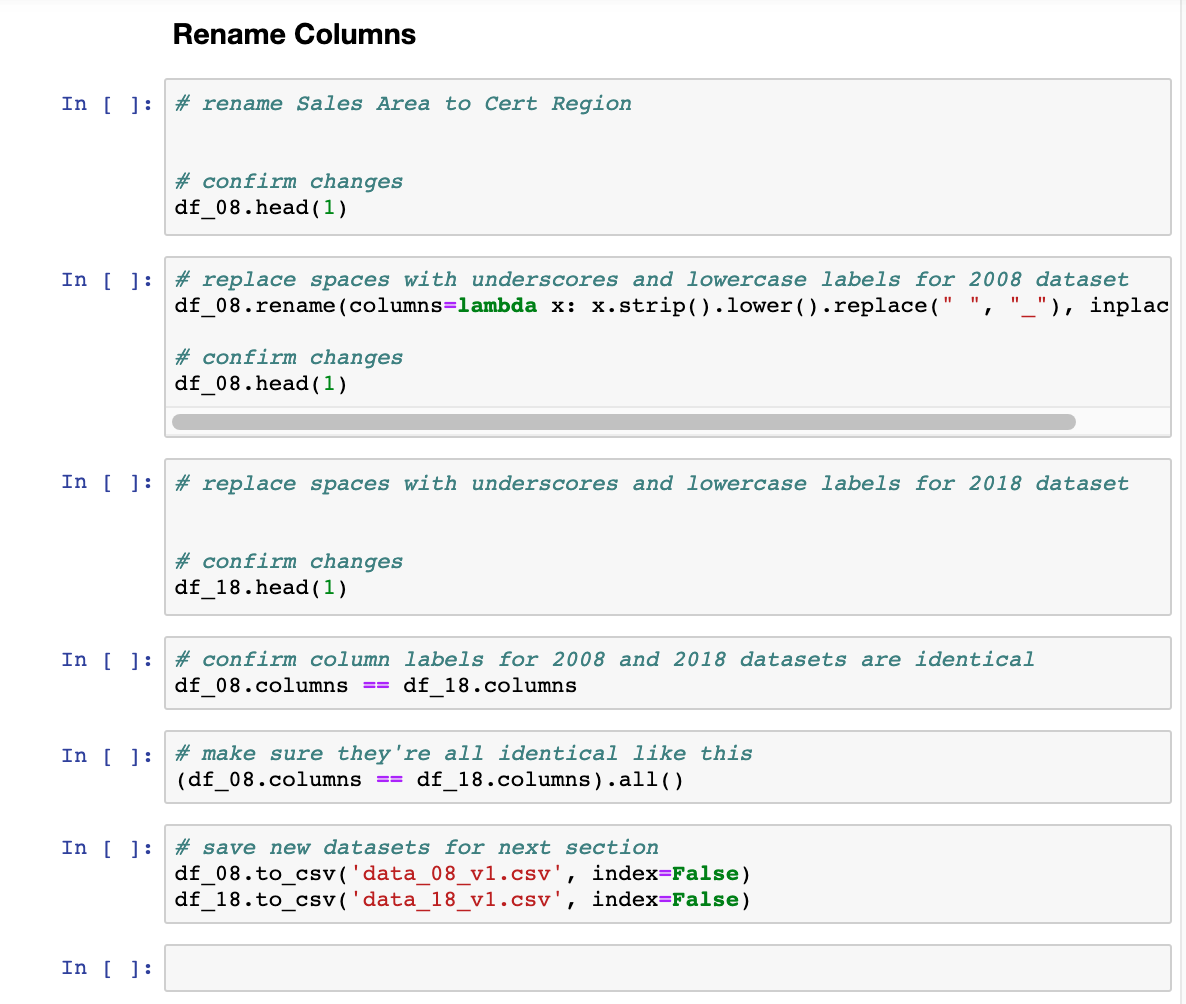
2. Rename Columns
- Change the "Sales Area" column label in the 2008 dataset to "Cert Region" for consistency.
- Rename all column labels to replace spaces with underscores and convert everything to lowercase. (Underscores can be much easier to work with in Python than spaces. For example, having spaces wouldn't allow you to use
df.column_nameinstead ofdf['column_name']to select columns or usequery(). Being consistent with lowercase and underscores also helps make column names easy to remember.)
df_08.drop(['Stnd', 'Underhood ID', 'FE Calc Appr', 'Unadj Cmb MPG'], axis=1, inplace=True)
# replace spaces with underscores and lowercase labels for 2008 dataset
df_08.rename(columns=lambda x: x.strip().lower().replace(" ", "_"), inplace=True)